
LLM Data Connectors
Thoughts on the current and future state of tooling for connecting LLMs to external data sources

This document brainstorms the current and future states of data connectors for large language models. Multiple different libraries have started implementing data connectors because having access to data sources is necessary for each of the libraries to function and no best-in-place solution exists today. Examples include langchain's document loaders, Llama Hub Data Connectors, and UnstructuredIO's Data Connectors. However, the implementation of data connectors is not the core competency of any of these libraries, so coupling data connectors with one of these libraries risks a suboptimal solution of data connectors. There are also some products/services that were not purpose-built for LLMs, but have made significant investment in the implementation of data connectors for other applications like ETL/ELT pipelines - including Airbyte and Zapier.
Given this scattering of implementations and a recent Twitter thread by Brian Raymond, I thought it would be a good time to step back and think about the principles of data loaders/data connection and where this functionality should live.
Why do we need Data Loaders?
Data loaders have become an important topic for LLM application developers who have some (e.g. python) process running on a host that is orchestrating a series of calls to (external) language models and (external) data sources. Although modern language models encode a huge amount of data via the data they were trained on, they still need external data sources exist for two main reasons:
Data Freshness - language models only encode data up to the time point they were trained on and need to pull the latest data, e.g. current stock prices
Private Data - some data sources are not publicly available for the training of foundation models and need to be accessed with authentication, e.g. customer data.
You might ask - what's wrong with each application just implementing a connector to the applications they need? Why do we need a one-stop shop for data loaders?
For applications that only need access to a few data sources, that may be just fine. However, centralizing this into a single service/platform will have multiple advantages:
Reliability - the data sources our applications are connecting to are liable to change at any time.
Ease of Implementation - there's simply no reasons to re-implement basic integration code if it's already been done
Security - centralized connection and auth providers are easier to trust for new customers
A useful analogy here is to look at what Plaid has done to connect the long tail of financial institutions. Plaid implemented a service that makes it easy for financial technology applications to connect to over 12,000 financial institutions like banks, credit unions, and investment companies. Any one of the apps using Plaid could implement these connections themselves, but it is simply not worth it at the scale of thousands of connections - not to mention the liability of securing customer credentials and ensuring the reliability of transfers.
What is a Data Connector?
Let's pause for a moment to answer what seems like a simple question - what is a data loader? A button click + keyboard presses on a webpage? An HTTP call that loads a webpage? A service python library? ... Yes! Any and all of these! In most cases you can also think of data connector as a “tool” that intelligent “agents” (like LLMs) can use. More on this idea of a tool later, but I may refer to them somewhat interchangeably throughout.
Since we are trying to find a general solution to loading data into an LLM application (i.e. Python, maybe Javascript, process) every data connector eventually needs to translate into a function call + some arguments. So, those examples above become something like
Button click + Keyboard Presses ==>
document.getElementById("my-button").clickHTTP Request ==>
requests.get(url)Service-Specific Python Library ==>
tweepy.api.user_timeline(screen_name="user", count=10)
I picked these 3 examples (UI interaction, web requests, and service-specific libraries) intentionally because I see them as 3 different layers of abstraction and generalization that data connectors/tools can work upon.
[Highest Layer of Abstraction] UI Interaction - this is where we, humans, normally interact. If you can get your application to navigate the web successfully, read in all of this UI data and generate the functions to interact with it, you will be able to do anything people to today. Doing all of that, however, is not necessarily the most efficient or easy approach, but interesting research like WebGPT is showing a lot of promise.
[Medium Layer of Abstraction] HTTP Call - this sits somewhere in the middle. You might be able to find a specific HTTP endpoint that loads your exact piece of data that would otherwise being embedded in the overall UI, but the API interface isn't wrapped in a library meant for 3rd party developer consumption.
[Lowest Layer of Abstraction] Service specific library - if a specific library for the service you want to interact with exists, great! An example here would be UnstructuredIO’s Data Connectors with CLIs and APIs purpose-built for use with LLMs. This approach will probably have exactly the set of APIs you need and return exactly what you want, but we need a large updated library to capture all possible data sources.
All that to say, the data connector library will need to think carefully about what level of abstraction at which it tries to implement its connectors. Too low and it may not be able to connect all data sources, too high at it may be ineffective at pulling in the right data. Maybe some combination is needed?
Current LLM Data Stack
Next, let's see where this data connector/data loader layer fits into the overall data stack for large language models. Two primary workflows have emerged so far for pulling data into LLM application chains:
[Index+Chat Your Data] Pre-processing some external dataset into a self-hosted data structure that is easily queryable by the LLM-based application before the application needs the data - i.e. an LLM focused ETL pipeline. LangChain recently hosted a Chat Your Data competition that resulted in lots of great examples of this pipeline.
[Agents with Tools] Fetching a single piece of data from an external data source as the application decides it is needed - this is often thought more of as the use of a "tool" I mentioned earlier. There isn’t widespread consensus today about the distinction between tools and data connectors today, but I currently think of data connectors as a subset of tools an agent can use. You can learn more about langchain’s use of agents here.
These two flows share some of the same steps and libraries, but differ in their order of operations and when they run. The Index+Chat pipeline essentially has two data connection steps - first getting outside data loaded into a new data store and second loading a specific piece of data into the application itself. The Agent workflow only has the later.
Below are two visualizations of the logical data pipelines along with one example service that supports each operation today.
Pre-Processing Dataset with Ingestion Pipeline

Fetching Data at Workflow Run Time with a Tool
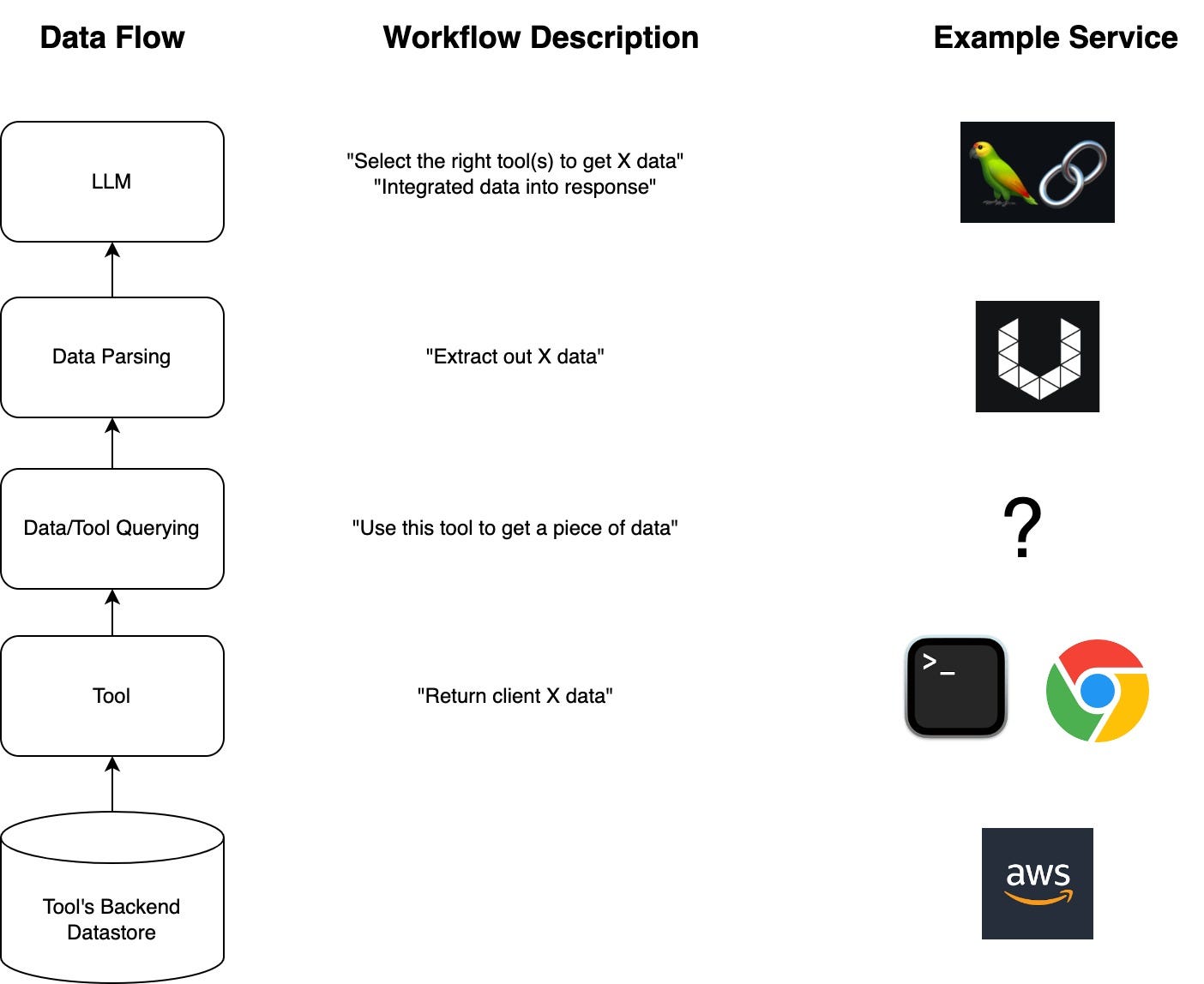
Data Connector Workflow
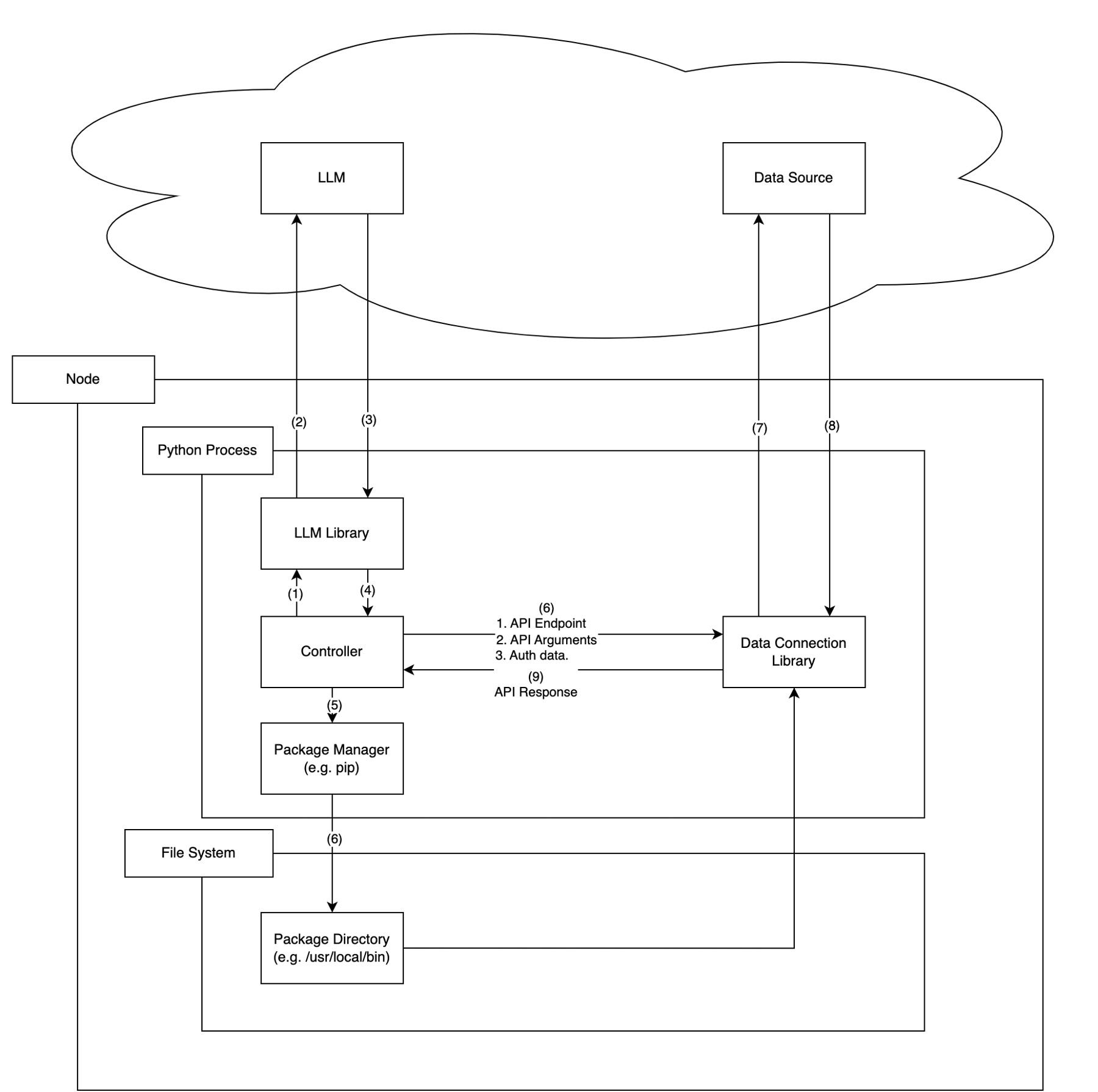
To get just a little more into the nitty-gritty code level of what code is run I think it’s useful to look at the step-by-step workflow for a single request. For those who haven’t played around with LLMs as agents who can select their own tools (i.e. data connector in this case), see this ChatGPT interaction for how you can use few-shot prompting to get an LLMs to choose an external data source it wants to pull data from.

When the orchestrator determines it needs to access some external data source, it will go through the following steps:
[Classification] Determine which data loader to use - this often, but doesn't have to, come as an output from the LLM itself choosing which "tool" it wants to use
[Availability Check] Determine whether the current process is able to access that tool and install additional packages if needed
[Access] Connect to and authenticate with the tool
[Data Request] Generate the appropriate code to call the specific desired function with appropriate parameters
[Retrieve Data and Integrate] Depending on the application, there will be some sort of parsing of the data returned and integrating it (potentially with another call to the LLM) into the final response
Feature Requirements for Data Loaders
Given everything above, here are the set of requirements I would like to see fulfilled by a one-stop-shop of data connectors:
Broad Data Access - I can easily connect to a huge variety of data sources via a common library. Not just the common ones re-implemented in multiple projects, but the entire long tail.
Service Discovery - I am able to get my language model to be aware of all of the APIs/functions exposed by this library so the LLM is able to output code using those APIs. At a small scale I can inject the full list into my prompt, but won’t be able to do that when trying to use thousands of connectors. Because of this, I think making the full list of open connectors open-source and part of LLM training data will be essential.
Security - authentication is handled by the library/service itself so I don't have to handle user credentials directly or get users to re-enter their credentials for every application.
Reliability - if any of the downstream data sources change their API contract, the library is quickly updated with the change. Again, open-source is a good route to enable these quick fixes.
Efficiency - Particularly for the Index+Chat workflow, ingesting data efficiently will be important. I’m not yet sure how to balance the generality (i.e. UI) vs specificity (i.e. source specific library) tradeoff, but I think it will come down to a combination of using custom libraries when available and falling back to generic methods when they are not.
Conclusions
My conclusion is that there's still a lot of open room for a go-to source of data connectors - the "Plaid for AI data". The likely outcomes seem to be:
UnstructuredIO moves "down the stack" and becomes the go-to source for data connection and data parsing given their existing position one layer up from data connection
A new startup dedicated to being the "Plaid for LLMs" pops up
An entrenched player like Zapier or Airbyte uses their existing position to win over the LLM community
Any even crazier idea... Plaid implements this and becomes "a data transfer network that powers digital finance and digital intelligence."
GPT-4 or another next-gen language model gets good enough that it doesn’t need custom libraries built up around tooling - you simply give it access to the python interpreter and it generates all connections you could need out-of-the-box
Special thank you to Lee James and Amir Mola for early feedback on this post!